Room no. 308
The room of our random experiments
Reward Learning through Ranking Mean Squared Error
by Chaitanya Kharyal
This page is meant to compile all the unpublished results relevant to my paper Reward Learning through Ranking Mean Squared Error. In case of any issues, or questions, you can reach out to me through my email.
Performance on MetaWorld Tasks
A reviewer rightly pointed out that all our results are on either OpenAI Gym Mujoco, or Deepmind Control suite. Even though these environments are standard in reward learning, we decided to test R4 on metaworld. On metaworld, R4’s advantage over RbRL does not seem to be as heavy as the other environments, even though it still outperforms RbRl in one out of three tested environments while perfornming comparatively in other two:
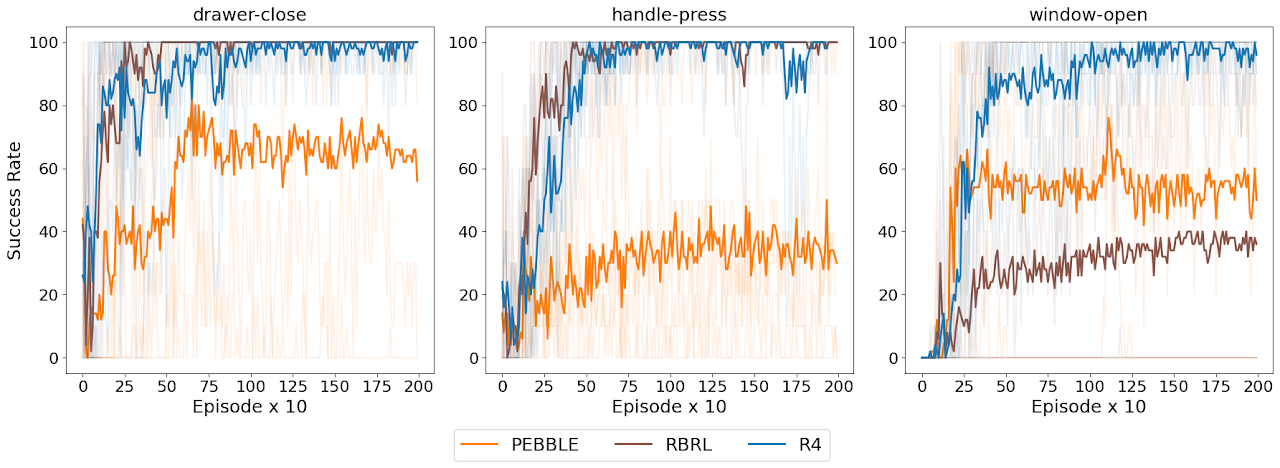
Apart from metaworld, we had previously tested R4 on lunar lander (discrete action space) and hungry-thirsty (tabular environment) in our workshop paper.
Performance using other Ranking Operators
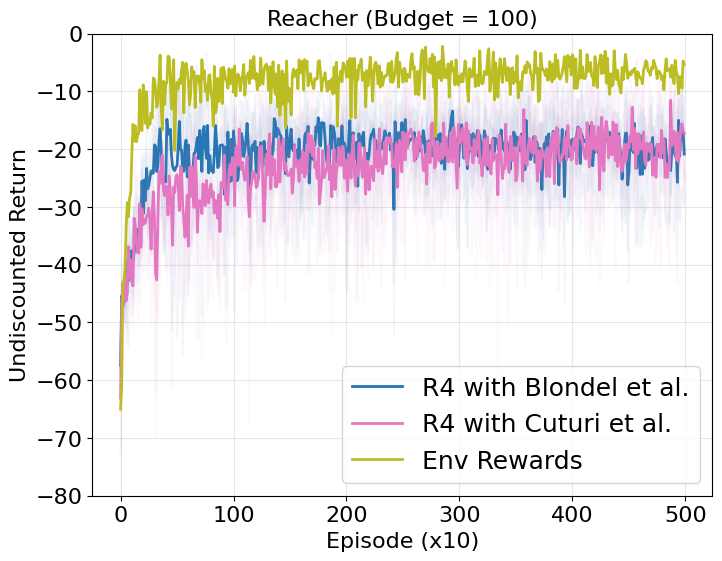
In our paper, we used the fast differentiable ranking operator(Blondel et al.) as our primary differntiable ranking algorithm. A reviewer rightly pointed out that we might be overfitting to that specific ranking operator, and the performance might not generalize to other ranking algorithms. Although rMSE objective does not explicitly care about the ranking algorithm, and the main purpose of this paper was not to show that the performance generalizes across the ranking operators, we tested R4 using another ranking operator (Cuturi et al.), and did not find significant difference in performance: